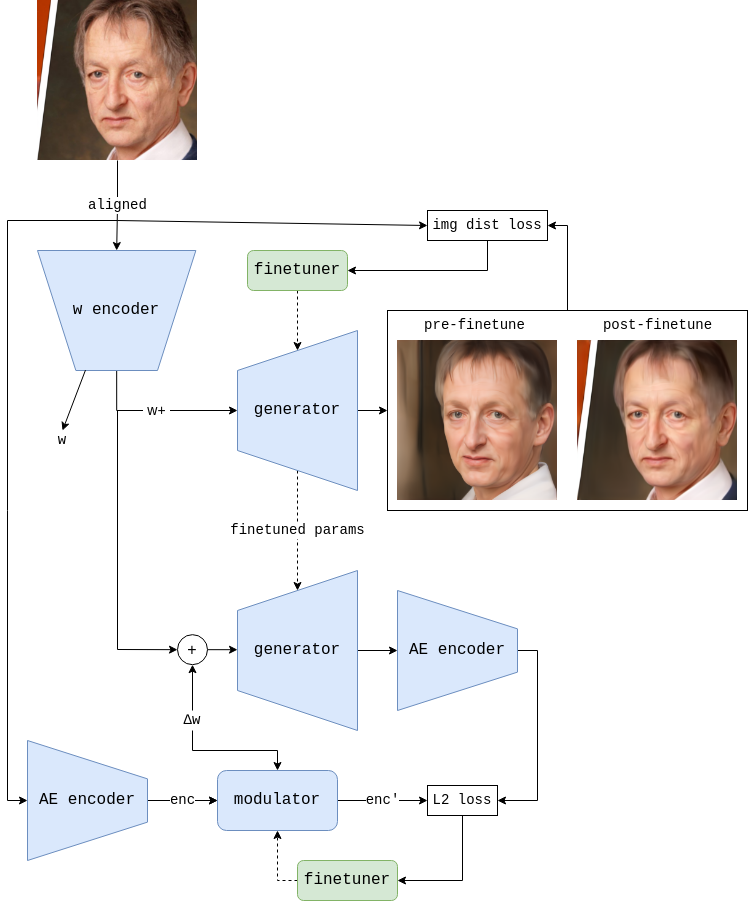
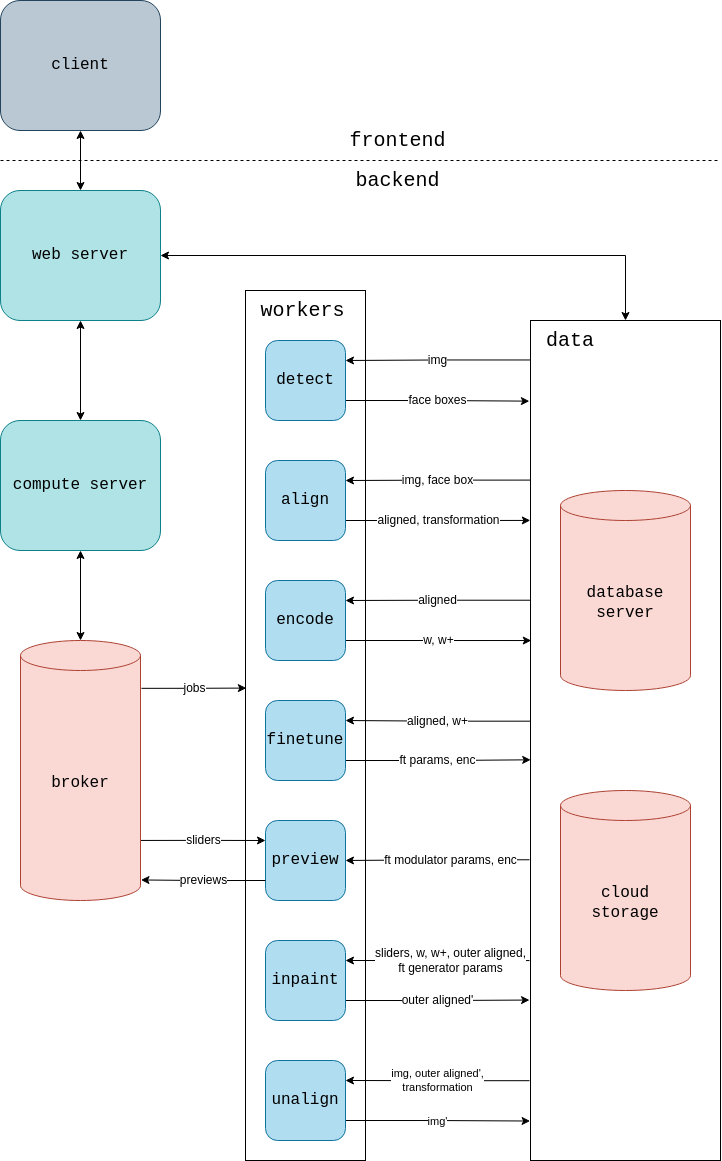
Step 4 - Encode
The aligned image is passed to the encoder to predict w (a vector in the disentangled latent space of StyleGAN2, size 512) and w+ (the extended latent space, size 18x512).
The encoder was trained to minimize the image distance between the input image and the generator output. There’s also a regularization term in the loss function to encourage the encoder to minimize the magnitude of ∆w+ (the distance between w and w+), thus preserving editability.
Image distance is defined as a weighted sum of the L2 distance in the pixel space, the L1 distance in the intermediate feature space of a pretrained VGG-19, and the negative cosine similarity in the output embedding space of a facial recognition model.
Step 5 - Finetune
The parameters of the generator are finetuned such that w+ results in a more faithful reconstruction of the target image.
Step 6 - Distill
The modulator is finetuned such that it can approximate finetuned StyleGAN2 image edits in the intermediate feature space of an adversarial autoencoder.
The autoencoder was trained to compress 256x256 aligned face images into a 512x4x4 encoding then reconstruct them according to the image distance metric mentioned earlier, plus an adversarial loss from a discriminator.
The modulator was trained to convert autoencoder encodings according to a delta in the latent space of StyleGAN2. It consists of a sequence of ResNet blocks modulated by Adaptive Layer-Instance Normalization.